Using LLMs #
Below are some ways to go beyond just LLMs and use your custom data. These include methods such as Retrieval Augmented Generation (RAG), finetuning, and even searching over tabular data.
Prompt Engineering #
LLMs are trained on a ton of text, so we can often get a lot out of them just by clever prompting. Finding the best way to prompt a model is also known as prompt engineering, and there are several popular methods, including chain-of-thought (including the model’s reasoning step-by-step) as well as few-shot prompting (providing a few sample examples).
Retrieval Augmented Generation #
Language models are typically pretrained on vast amounts of data, but they may require updated information or data tailored to a specific use case. Retraining a language model on a large amount of data might prove to be expensive. In many scenarios, extending large language models with external knowledge bases becomes essential to provide relevant and accurate outputs. This is where Retrieval-Augmented Generation (RAG) comes into play. RAG consists of two key components: a retrieval system to identify relevant items or contextual information and a mechanism to integrate that information into the model’s output, often through prompting.
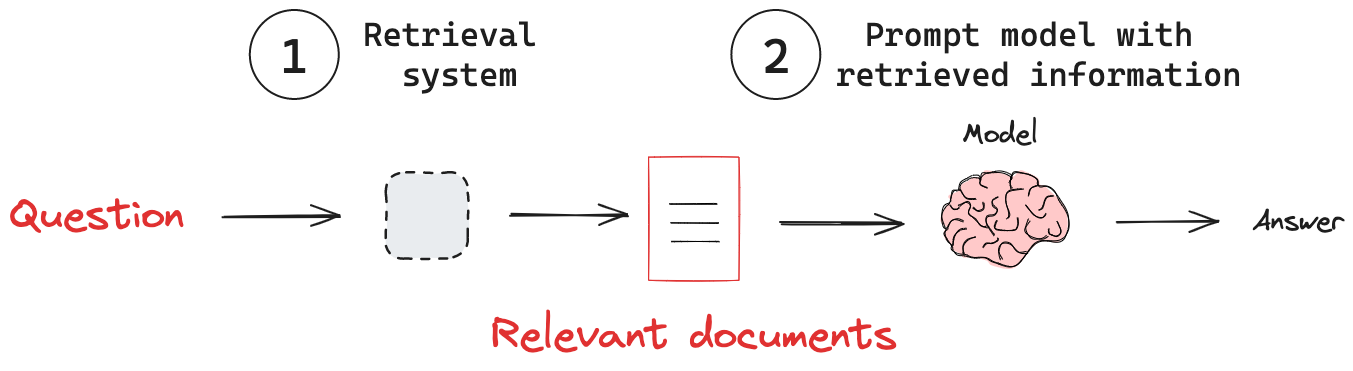
To implement a knowledge base for RAG, you often use an embedding model, which encodes information into a lower-dimensional space, and a vector database, which performs similarity searches within that space. Tools like Chroma, Pinecone, and pgvector are popular options for this purpose. These systems enable efficient retrieval of contextually relevant data to enhance the model’s responses. Below is a simple code example demonstrating this process, and you can find several excellent tutorials for further exploration.
# Make sure to pip install chromadb openai
import chromadb
from chromadb.utils import embedding_functions
from chromadb.config import Settings
# Step 1: Initialize the Chroma client
chroma_client = chromadb.Client(
Settings(
persist_directory="./chroma_db", # Path to store the database
chroma_db_impl="duckdb+parquet", # Database backend
)
)
# Step 2: Define the embedding function (OpenAI in this case)
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key="your_openai_api_key", # Replace with your OpenAI API key
model_name="text-embedding-ada-002",
)
# Step 3: Create or get a collection
collection = chroma_client.get_or_create_collection(
name="knowledge_base", embedding_function=openai_ef
)
# Step 4: Add data to the collection
documents = [
"The Eiffel Tower is located in Paris, France.",
"The Great Wall of China is one of the Seven Wonders of the World.",
"Python is a popular programming language for machine learning.",
"The Amazon Rainforest is the largest rainforest in the world.",
"Albert Einstein developed the theory of relativity."
]
doc_ids = [f"doc_{i}" for i in range(len(documents))]
collection.add(
documents=documents,
ids=doc_ids
)
# Step 5: Query the collection with a similar question
query = "Who created the theory of relativity?"
results = collection.query(
query_texts=[query],
n_results=3 # Return top 3 most similar results
)
# Step 6: Display results
print("Query:", query)
print("Most similar documents:")
for i, doc in enumerate(results["documents"][0]):
print(f"{i + 1}. {doc}")
Using these documents, we can then use them when prompting a final language model to improve overall responses.
Finetuning Language Models #
Sometimes, prompting isn’t enough. You may want to adjust and steer the tone of a large language model (LLM) or train it on additional examples that exceed the limits of a single prompt. To achieve this, fine-tuning is a powerful tool.
Fine-tuning is the process of adapting a pre-trained model for specific tasks or use cases. It is significantly easier and more cost-effective to improve a base model through fine-tuning than to train a model from scratch.
During rapid prototyping, you’ll likely rely on a pre-trained LLM. If needed, there are well-documented ways to fine-tune pre-trained LLMs (OpenAI Fine-Tuning Guide). The most important steps in fine-tuning include:
- Preparing your data: Ensure your dataset is in the correct format, and include both positive and negative examples so the LLM can learn to handle a variety of scenarios effectively.
- Choosing the right dataset size: A minimum of 10 examples can be sufficient, but you’ll observe clearer improvements with 50–100 examples or more.
- Setting up evaluations: Create a set of prompts that can be used to test and measure the fine-tuned model’s performance against your desired outcomes.
Once the data and evaluations are ready, you can initiate a fine-tuning job using OpenAI’s API:
from openai import OpenAI
client = OpenAI()
job = client.fine_tuning.jobs.create(
training_file="file-all-about-the-weather",
model="gpt-4o-2024-08-06",
method={
"type": "dpo",
"dpo": {
"hyperparameters": {"beta": 0.1},
},
},
)
After fine-tuning, you can use the customized model in your application:
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="ft:gpt-4o-mini:my-org:custom_suffix:id",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)
You can experiment with different hyperparameters to improve the performance of your fine-tuned model. Fine-tuning an open-source model is also a viable option. There are excellent resources available, such as the Llama Fine-Tuning Guide. Additionally, there are many techniques (IBM Fine-Tuning Techniques) to make the process more cost-effective and computationally efficient.
Function Calling/Tool Use #
We showed above how we might incorporate external data in our LLM pipelines. However, we may also need for our model to interact with other services, such as APIs and UIs. In this case, we’ll lean on function calling, or tool use.
The below diagram gives a good overview of how to set up function calling, with many of the popular pre-trained LLMs already having infrastructure to enable this. In general, you will need to: define the tools to the LLM, determine when to call the tool, and use the results downstream.
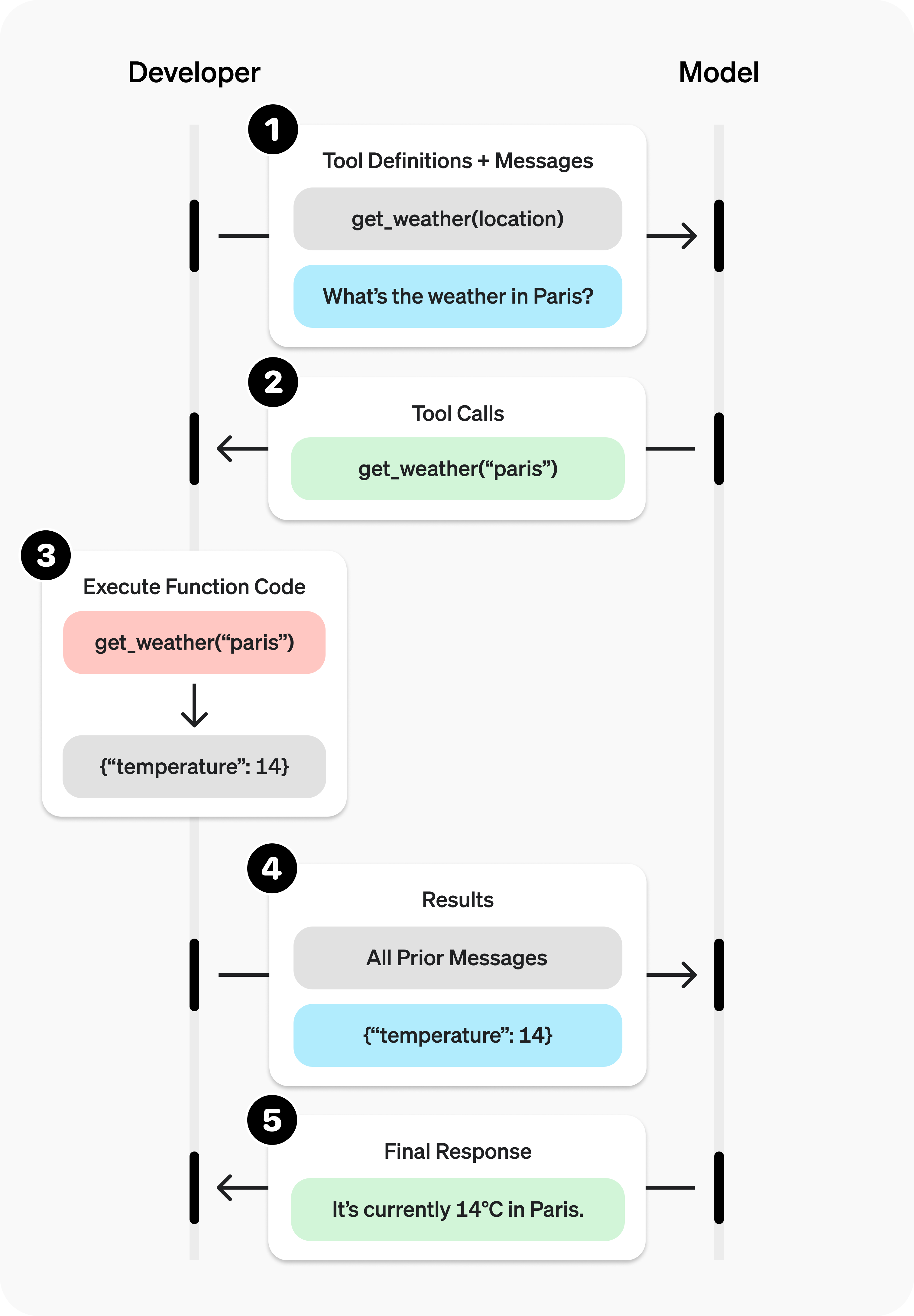
As a quick example, let’s first implement a function that gets the current weather using an API call:
import requests
def get_weather(latitude, longitude):
response = requests.get(f"https://api.open-meteo.com/v1/forecast?latitude={latitude}&longitude={longitude}¤t=temperature_2m,wind_speed_10m&hourly=temperature_2m,relative_humidity_2m,wind_speed_10m")
data = response.json()
return data['current']['temperature_2m']
Using the openai SDK, we can then define this tool for our language model to use:
from openai import OpenAI
import json
client = OpenAI()
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current temperature for provided coordinates in celsius.",
"parameters": {
"type": "object",
"properties": {
"latitude": {"type": "number"},
"longitude": {"type": "number"}
},
"required": ["latitude", "longitude"],
"additionalProperties": False
},
"strict": True
}
}]
messages = [{"role": "user", "content": "What's the weather like in Paris today?"}]
completion = client.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=tools,
)
If the model decides to use the tool, it’ll respond to the message with a request to get the weather:
[{
"id": "call_12345xyz",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"latitude\":48.8566,\"longitude\":2.3522}"
}
}]
We can then execute the function code:
tool_call = completion.choices[0].message.tool_calls[0]
args = json.loads(tool_call.function.arguments)
result = get_weather(args["latitude"], args["longitude"])
And then supply the result to the model and call it again.
messages.append(completion.choices[0].message) # append model's function call message
messages.append({ # append result message
"role": "tool",
"tool_call_id": tool_call.id,
"content": result
})
completion_2 = client.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=tools,
)
Overall, function calling is how we enable the development of truly agentic workflows.